Veien til å bli en dyktig og vellykket programmerer er vanskelig, men en som absolutt er oppnåelig. Datastrukturer er en kjernekomponent som hver programmeringsstudent må mestre, og sjansen er stor for at du allerede har lært eller jobbet med noen grunnleggende datastrukturer som matriser eller lister.
Intervjuere har en tendens til å foretrekke å stille spørsmål relatert til datastrukturer, så hvis du forbereder deg på et jobbintervju, må du friske opp kunnskapen din om datastrukturer. Les videre når vi lister opp de viktigste datastrukturene for programmerere og jobbintervjuer.
Koblede lister er en av de mest grunnleggende datastrukturene og ofte utgangspunktet for studenter i de fleste datastrukturemner. Koblede lister er lineære datastrukturer som tillater sekvensiell datatilgang.
Elementer i den koblede listen lagres i individuelle noder som er koblet sammen (lenket) ved hjelp av pekere. Du kan tenke på en koblet liste som en kjede av noder koblet til hverandre via forskjellige pekere.
I slekt: En introduksjon til bruk av koblede lister i Java
Før vi kommer inn på detaljene til de ulike typene koblede lister, er det avgjørende å forstå strukturen og implementeringen av den enkelte node. Hver node i en koblet liste har minst én peker (dobbeltkoblede listenoder har to pekere) som kobler den til neste node i listen og selve dataelementet.
Hver koblet liste har en hode- og halenode. Enkeltkoblede listenoder har bare én peker som peker til neste node i kjeden. I tillegg til neste peker, har dobbeltkoblede listenoder en annen peker som peker til forrige node i kjeden.
Intervjuspørsmål knyttet til koblede lister dreier seg vanligvis om innsetting, søking eller sletting av et spesifikt element. Innsetting i en koblet liste tar O(1) tid, men sletting og søking kan i verste fall ta O(n) tid. Så koblede lister er ikke ideelle.
2. Binært tre
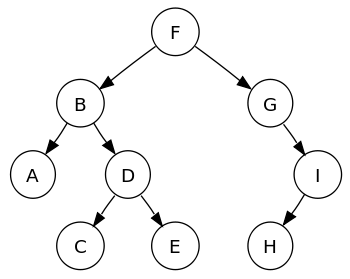
Binære trær er den mest populære undergruppen av trefamiliens datastruktur; elementer i et binært tre er ordnet i et hierarki. Andre typer trær inkluderer AVL, rød-svarte, B-trær, etc. Noder i det binære treet inneholder dataelementet og to pekere til hver underordnede node.
Hver overordnet node i et binært tre kan ha maksimalt to underordnede noder, og hver underordnede node kan på sin side være en forelder til to noder.
I slekt: En nybegynnerguide til binære trær
Et binært søketre (BST) lagrer data i en sortert rekkefølge, der elementer med en nøkkelverdi mindre enn den overordnede noden lagres til venstre, og elementer med en nøkkelverdi større enn overordnet node lagres på Ikke sant.
Binære trær blir ofte spurt i intervjuer, så hvis du gjør deg klar for et intervju, bør du vite hvordan du flater ut et binært tre, slår opp et spesifikt element og mer.
3. Hash-tabell
Hash-tabeller eller hash-kart er en svært effektiv datastruktur som lagrer data i et matriseformat. Hvert dataelement tildeles en unik indeksverdi i en hashtabell, som muliggjør effektiv søking og sletting.
Prosessen med å tilordne eller tilordne nøkler i et hashkart kalles hashing. Jo mer effektiv hash-funksjonen er, desto bedre effektivitet har selve hashtabellen.
Hver hashtabell lagrer dataelementer i et verdiindekspar.
Der verdi er dataene som skal lagres, og indeks er det unike heltall som brukes for å kartlegge elementet i tabellen. Hash-funksjoner kan være svært komplekse eller veldig enkle, avhengig av den nødvendige effektiviteten til hashtabellen og hvordan du vil løse kollisjoner.
Kollisjoner oppstår ofte når en hash-funksjon produserer samme kartlegging for forskjellige elementer; hash-kartkollisjoner kan løses på forskjellige måter, ved å bruke åpen adressering eller kjetting.
Hash-tabeller eller hash-kart har en rekke forskjellige applikasjoner, inkludert kryptografi. De er førstevalgsdatastrukturen når det kreves innsetting eller søk i konstant O(1)-tid.
4. Stabler
Stabler er en av de enklere datastrukturene og er ganske enkle å mestre. En stabeldatastruktur er i hovedsak enhver virkelig stabel (tenk på en stabel med bokser eller plater) og fungerer på en LIFO-måte (Last In First Out).
Stacks' LIFO-egenskap betyr at elementet du satte inn sist vil få tilgang først. Du kan ikke få tilgang til elementer under det øverste elementet i en stabel uten å sette elementene over det.
Stabler har to primære operasjoner – push og pop. Push brukes til å sette inn et element i stabelen, og pop fjerner det øverste elementet fra stabelen.
De har også mange nyttige applikasjoner, så det er veldig vanlig at intervjuere stiller spørsmål knyttet til stabler. Å vite hvordan man reverserer en stabel og evaluerer uttrykk er ganske viktig.
5. Køer
Køer ligner på stabler, men fungerer på en FIFO-måte (First In First Out), noe som betyr at du kan få tilgang til elementene du satte inn tidligere. Kødatastrukturen kan visualiseres som en hvilken som helst kø i det virkelige liv, der folk plasseres basert på deres ankomstrekkefølge.
Innsettingsoperasjon av en kø kalles enqueue, og sletting/fjerning av et element fra begynnelsen av køen kalles dequeuing.
I slekt: En nybegynnerveiledning for å forstå køer og prioriterte køer
Prioritetskøer er en integrert applikasjon av køer i mange vitale applikasjoner som CPU-planlegging. I en prioritert kø blir elementene ordnet i henhold til deres prioritet i stedet for ankomstrekkefølgen.
6. Dynger
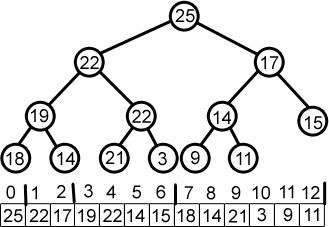
Hauger er en type binærtre der noder er ordnet i stigende eller synkende rekkefølge. I en Min Heap er nøkkelverdien til overordnet lik eller mindre enn dens underordnede verdi, og rotnoden inneholder minimumsverdien for hele haugen.
På samme måte inneholder rotnoden til en Max Heap den maksimale nøkkelverdien til heapen; du må beholde min/maks haug-egenskapen gjennom hele haugen.
I slekt: Dynger vs. Stabler: Hva skiller dem fra hverandre?
Hauger har mange bruksområder på grunn av deres svært effektive natur; primært implementeres prioriterte køer ofte gjennom heaps. De er også en kjernekomponent i heapsort-algoritmer.
Lær datastrukturer
Datastrukturer kan virke opprivende i begynnelsen, men bruker nok tid, og du vil finne dem enkle som en plett.
De er en viktig del av programmering, og nesten alle prosjekter krever at du bruker dem. Å vite hvilken datastruktur som er ideell for et gitt scenario er kritisk.
Disse algoritmene er avgjørende for hver programmerers arbeidsflyt.
Les Neste
- Programmering
- Dataanalyse
- Kodetips

Fahad er forfatter ved MakeUseOf og studerer for tiden informatikk. Som en ivrig teknologiskribent sørger han for at han holder seg oppdatert med den nyeste teknologien. Han er spesielt interessert i fotball og teknologi.
Abonner på vårt nyhetsbrev
Bli med i vårt nyhetsbrev for tekniske tips, anmeldelser, gratis e-bøker og eksklusive tilbud!
Klikk her for å abonnere

