Annonse
Vi kan snakke med nesten alle dingsene våre nå, men hvordan fungerer det? Når du spør "Hvilken sang er dette?" eller si "Ring mamma", det skjer et mirakel av moderne teknikk. Og selv om det føles som om det er i front, går denne ideen om å snakke med enheter flere tiår tilbake - nesten så langt som jetpacks i science fiction!
I dag er hoveddelen av oppmerksomheten rundt stemmestyrt databehandling på smarttelefoner. Apple, Amazon, Microsoft og Google er øverst i kjeden, og hver tilbyr sin egen måte å snakke med elektronikk på. Du visste hvem de er: Siri, Alexa, Cortana og det navnløse “Ok, Google”. Noe som reiser et stort spørsmål ...
Hvordan tar en enhet talte ord og gjør dem om til kommandoer den kan forstå? I bunn og grunn kommer det ned på mønstermatching og komme med spådommer basert på disse mønstrene. Mer spesifikt er stemmegjenkjenning en kompleks oppgave kommer fra Akustisk modellering og Språkmodellering.
Akustisk modellering: Bølgeformer og telefoner
Akustisk modellering er prosessen med å ta en bølgeform av tale og analysere den ved hjelp av statistiske modeller. Den vanligste metoden for dette er
Skjult Markov-modellering, som brukes i det som kalles uttale modellering å dele opp talen i komponentdeler som kalles telefoner (ikke forveksles med faktiske telefonenheter). Microsoft har vært en ledende forsker på dette feltet i mange år.Skjult Markov-modellering: sannsynlighetsstater
Skjult Markov-modellering er en prediktiv matematisk modell der gjeldende tilstand bestemmes ved å analysere utgangen. Wikipedia har en flott eksempel ved å bruke to venner.
Se for deg to venner - Local Friend og Remote Friend - som bor i forskjellige byer. Local Friend vil finne ut hvordan været er der Remote Friend bor, men Remote Friend vil bare snakke om hva han gjorde den dagen: gå, shoppe eller rydde. Sannsynligheten for hver aktivitet avhengig av dagens vær.
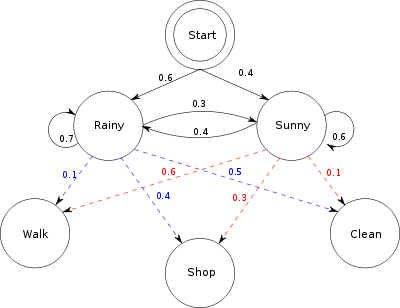
Later som om dette er den eneste tilgjengelige informasjonen. Med det kan Local Friend finne trender i hvordan været endret seg fra dag til dag, og ved å bruke disse trendene, hun kan begynne å gjøre utdannede gjetninger om hva dagens vær vil være basert på venninnens aktivitet i går. (Du kan se et diagram over systemet over.)
Hvis du vil ha et mer komplekst eksempel, sjekk ut dette eksemplet på Matlab. Ved stemmegjenkjenning sammenligner denne modellen i hovedsak hver del av bølgeformen mot det som kommer før og hva som kommer etter, og mot en ordbok med bølgeformer for å finne ut hva som blir sagt.
I utgangspunktet, hvis du lager en "th" lyd, vil den sjekke den lyden mot de mest sannsynlige lydene som vanligvis kommer før og etter den. Kanskje det betyr å sjekke mot “e” lyden, “at” lyden og så videre. Når mønsteret stemmer overens, har det hele ordet. Dette er en forenkling, men du kan se Microsofts hele forklaring her.
Språkmodellering: mer enn lyd
Akustisk modellering går langt i å hjelpe datamaskinen din til å forstå deg, men hva med homonymer og regionale variasjoner i uttalen? Det er der språkmodellering spiller inn. Google har drevet mye forskning på dette området, hovedsakelig gjennom bruk av N-gram modellering.
Når Google prøver å forstå talen din, gjør den det basert på modeller hentet fra den enorme banken med talesøk og YouTube-transkripsjoner. Alle disse morsomt gale videoklippene har faktisk hjulpet Google med å utvikle ordbøkene sine. Også brukte de avdøde GOOG-411 for å samle informasjon om hvordan folk snakker.

Hele denne språksamlingen skapte et stort utvalg av uttaler og dialekter, noe som skapte en robust ordbok og hvordan de høres ut. Dette gir mulighet for kamper som har en sterkt redusert feilrate enn brute force matching basert på rå sannsynligheter. Du kan lese en kort artikkel som beskriver metodene deres her.
Selv om Google er ledende på dette feltet, er det andre matematiske modeller som utvikles, inkludert kontinuerlig plass modeller og posisjonsspråklige modeller, som er mer avanserte teknikker født fra forskning innen kunstig intelligens. Disse metodene er basert på å gjenskape hva slags resonnement mennesker gjør når de lytter til hverandre. Disse er mye mer avanserte både når det gjelder teknologien bak dem, men også matte og programmering som er nødvendig for å kartlegge disse modellene.
N-Gram modellering: Sannsynlighet oppfyller minnet
N-gram modellering fungerer basert på sannsynligheter, men den bruker en eksisterende ordbok med ord for å lage et forgrenende tre av muligheter, som deretter glattes ut av hensyn til effektiviteten. På en måte betyr dette at N-gram Modeling fjerner mye av usikkerheten i den nevnte Hidden Markov Modeling.
Som nevnt ovenfor, kommer denne metodens styrke fra å ha en stor ordbok med ord og bruk, ikke bare primitivt lyder. Dette gir programmet muligheten til å fortelle forskjellen mellom homofoner, som "slå" og "rødbete". Det er kontekstuelt, som betyr at når du snakker om poengsummene i går, ikke programmet drar frem ord om borscht.
Men disse modellene er faktisk ikke de beste for språket, hovedsakelig på grunn av problemer med sannsynlighet for ord i lengre setninger. Når du legger til flere ord i en setning, blir denne modellen litt av da det ikke er sannsynlig at de tidlige ordene dine har lastet alt som trengs for din komplette tanke.
Imidlertid er det enkelt og enkelt å implementere, noe som gjør det til en perfekt match for et selskap som Google som liker å kaste servere på beregningsproblemer. Du kan lese videre om N-gram Modelieng på University of Washington, eller du kan se a forelesning på Coursera.
Shouting at Clouds: Apps & Devices
Alle som har brukt Siri kjenner frustrasjonen over en treg nettverkstilkobling. Dette er fordi kommandoene dine til Siri blir sendt over nettverket som skal dekodes av Apple. Cortana for Windows-telefon krever også en nettverkstilkobling for å fungere ordentlig. Derimot er Amazons Echo bare en Bluetooth-høyttaler uten noe internett.
Hvorfor forskjellen? Fordi Siri og Cortana trenger tunge servere for å avkode talen din. Kan det gjøres på telefonen eller nettbrettet ditt? Jada, men du vil drepe ytelsen din og batterilevetiden i prosessen. Det er bare mer fornuftig å laste ned behandlingen til dedikerte maskiner.
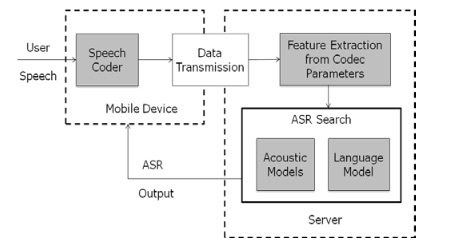
Tenk på det på denne måten: kommandoen din er en bil som sitter fast i gjørmen. Du kan sannsynligvis skyve det ut selv med nok tid og krefter, men det vil ta timer og etterlate deg utmattet. I stedet ringer du veihjelp og de drar bilen ut på bare noen få minutter. Ulempen er at du må ringe og vente på dem, men det er fortsatt raskere og mindre beskatning.
Desktop-modeller som Nuance pleier å bruke lokale ressurser på grunn av den kraftigere maskinvaren. Tross alt, med ordene til Steve Jobs, din desktop er en lastebil. (Noe som gjør det litt dumt at OS X bruker servere for behandling.) Så når du trenger å behandle språk og tale, er den allerede utstyrt godt nok til å håndtere det på egen hånd.
På den annen side lar Android utviklere inkludere talegjenkjenning offline i appene sine. Google liker å komme foran teknologien, og du kan satse på at de andre plattformene vil få denne muligheten etter hvert som maskinvaren deres blir kraftigere. Ingen liker det når dårlig dekning eller dårlig mottakelse lobotomiserer enheten deres.
Begynn å bruke talekommandoer nå
Nå som du kjenner de grunnleggende konseptene, bør du leke med de forskjellige enhetene dine. Prøv ut det nye stemmeskriving i Google Dokumenter Hvordan stemmetype er den nye beste funksjonen i Google DokumenterStemmegjenkjenning har forbedret seg med store sprang de siste årene. Tidligere denne uken introduserte Google endelig stemmetype i Google Dokumenter. Men er det noe bra? La oss finne det ut! Les mer . Som om Web office-pakken ikke allerede var kraftig nok, lar stemmestyring deg diktere og formatere dokumentene dine fullstendig. Dette utvides på den kraftige teknologien de allerede har designet for Chrome og Android.
Andre ideer inkluderer å sette opp din Mac for å bruke talekommandoer Slik bruker du talekommandoer på Mac-en Les mer og sette opp din Amazon Echo med automatisk kassa Hvordan Amazon Echo kan gjøre hjemmet ditt til et smart hjemSmart hjemme tech er fremdeles i de første dagene, men et nytt produkt fra Amazon kalt "Echo" kan være med på å bringe det inn i mainstream. Les mer . Lev i fremtiden og omfavn å snakke med dingsene dine - selv om du bare bestiller flere papirhåndklær. Hvis du er en smarttelefonavhengig, har vi også veiledninger til Siri 8 ting du sannsynligvis ikke visste at Siri kunne gjøreSiri har blitt en av iPhone's definerende funksjoner, men for mange mennesker er det ikke alltid det mest nyttige. Selv om noe av dette skyldes begrensningene i stemmegjenkjenning, er rart å bruke ... Les mer , Cortana 6 kuleste ting du kan kontrollere med Cortana i Windows 10Cortana kan hjelpe deg med å gå håndfri på Windows 10. Du kan la henne søke i filene dine og på nettet, gjøre beregninger eller trekke opp værmeldingen. Her dekker vi noen av de kulere ferdighetene hennes. Les mer , og Android OK, Google: 20 nyttige ting du kan si til din Android-telefonGoogle Assistant kan hjelpe deg med å gjøre mye på telefonen. Her er en hel haug med grunnleggende, men nyttige OK Google-kommandoer å prøve. Les mer .
Hva er din favorittbruk av stemmekontroll? Gi oss beskjed i kommentarene.
Bildetillegg: T-flex via Shutterstock, Terencehonles via Wikimedia Foundation, Arizona State, Cienpies Design via Shutterstock
Michael brukte ikke en Mac da de ble dømt, men han kan kode i Applescript. Han har grader innen informatikk og engelsk; han har skrevet om Mac, iOS og videospill i en stund nå; og han har vært IT-ape på dagtid i over et tiår, og har spesialisert seg på skripting og virtualisering.


