Annonse
I løpet av de siste månedene har du kanskje lest dekningen rundt en artikkel, medforfatter av Stephen Hawking, diskutere risikoen forbundet med kunstig intelligens. Artikkelen antydet at AI kan utgjøre en alvorlig risiko for menneskeheten. Hawking er ikke alene der - Elon Musk og Peter Thiel er begge intellektuelle offentlige personer som har uttrykt lignende bekymringer (Thiel har investert mer enn $ 1,3 millioner for å undersøke problemet og mulige løsninger).
Dekningen av Hawkings artikkel og Musks kommentarer har vært, for ikke å sette et for godt poeng på det, litt jovialt. Tonen har vært veldig mye "Se på denne rare tingen alle disse nerdene er bekymret for." Ideen om at noen av de smarteste menneskene på Jorden varsler deg om at noe kan være veldig farlig, kan det være lite verdt å lytte.
Dette er forståelig - kunstig intelligens som overtar verden høres absolutt veldig rart ut og umulig, kanskje på grunn av den enorme oppmerksomheten som allerede er gitt til denne ideen av science fiction forfattere. Så, hva har alle disse nominelt tilregnelige, rasjonelle menneskene så talt?
Hva er intelligens?
For å snakke om faren ved kunstig intelligens, kan det være nyttig å forstå hva intelligens er. For å forstå problemet bedre, la oss se på en leketøy AI-arkitektur som brukes av forskere som studerer resonnementsteorien. Denne leken AI kalles AIXI, og har en rekke nyttige egenskaper. Målene kan være vilkårlige, det skaleres godt med datakraft, og dets interne design er veldig rent og greit.
Videre kan du implementere enkle, praktiske versjoner av arkitekturen som kan gjøre ting som spille Pacman, hvis du vil. AIXI er produktet av en AI-forsker ved navn Marcus Hutter, uten tvil den fremste eksperten på algoritmisk intelligens. Det er ham som snakker i videoen over.
AIXI er overraskende enkel: den har tre kjernekomponenter: lærer, planner, og nyttefunksjon.
- De lærer tar inn strenger av biter som tilsvarer innspill om omverdenen, og søker gjennom dataprogrammer til den finner de som produserer observasjonene sine som utdata. Disse programmene, sammen, lar det gjette seg om hvordan fremtiden vil se ut, ganske enkelt ved å kjøre hver program fremover og vekt sannsynligheten for resultatet med lengden på programmet (en implementering av Occams Barberhøvel).
- De planner søker gjennom mulige handlinger som agenten kunne utføre, og bruker elevmodulen til å forutsi hva som ville skje hvis det tok hver av dem. Den rangerer dem deretter etter hvor gode eller dårlige de forutsagte resultatene er, og velger løpet av handling som maksimerer godheten til det forventede resultatet multiplisert med den forventede sannsynligheten for oppnå det.
- Den siste modulen, nyttefunksjon, er et enkelt program som tar inn en beskrivelse av en fremtidig tilstand i verden, og beregner en bruksgrad for den. Denne nyttepoengene er hvor bra eller dårlig dette resultatet er, og brukes av planleggeren til å evaluere fremtidig verdensstat. Nyttefunksjonen kan være vilkårlig.
- Sammenlagt danner disse tre komponentene en optimizer, som optimaliserer for et bestemt mål, uansett hvilken verden den befinner seg i.
Denne enkle modellen representerer en grunnleggende definisjon av en intelligent agent. Agenten studerer miljøet, bygger modeller av det og bruker deretter modellene for å finne handlingsforløpet som vil maksimere oddsen for at den får det den vil. AIXI ligner i struktur som en AI som spiller sjakk, eller andre spill med kjente regler - bortsett fra at den er i stand til å utlede spillereglene ved å spille det, med utgangspunkt i null kunnskap.
AIXI, gitt nok tid til å beregne, kan lære å optimalisere ethvert system for ethvert mål, uansett kompleks. Det er en generelt intelligent algoritme. Merk at dette ikke er det samme som å ha menneskelignende intelligens (biologisk inspirert AI er en helt annet tema Giovanni Idili fra OpenWorm: Hjerner, ormer og kunstig intelligensÅ simulere en menneskelig hjerne er en vei utenfor, men et åpen kildekode-prosjekt tar viktige første skritt ved å simulere nevrologi og fysiologi til et av de enkleste dyrene som er kjent for vitenskapen. Les mer ). Med andre ord, AIXI kan være i stand til å overliste ethvert menneske til enhver intellektuell oppgave (gitt nok datakraft), men den er kanskje ikke klar over seieren Tenkemaskiner: Hva nevrovitenskap og kunstig intelligens kan lære oss om bevissthetKan bygging av kunstig intelligente maskiner og programvare lære oss om bevissthetens virke og menneskets sinnes natur? Les mer .

Som en praktisk AI har AIXI mange problemer. For det første har det ingen måte å finne de programmene som gir utdataene den er interessert i. Det er en brute-force algoritme, som betyr at den ikke er praktisk hvis du ikke tilfeldigvis har en vilkårlig kraftig datamaskin som ligger rundt. Enhver faktisk implementering av AIXI er nødvendigvis en tilnærming, og (i dag) generelt en ganske rå. Likevel gir AIXI oss et teoretisk glimt av hvordan en kraftig kunstig intelligens kan se ut, og hvordan den kan resonnere.
Verdienes rom
Hvis har du gjort dataprogrammering Grunnleggende om dataprogrammering 101 - variabler og datatyperEtter å ha introdusert og snakket litt om objektorientert programmering før og hvor dens navnebror kommer fra, jeg trodde det er på tide at vi går gjennom de absolutte grunnleggende programmene i et ikke-språklig spesifikt vei. Dette... Les mer , vet du at datamaskiner er motbydelig, pedantisk og mekanisk bokstavelige. Maskinen vet eller bryr seg ikke hva du vil at den skal gjøre: den gjør bare det den har blitt fortalt. Dette er en viktig forestilling når vi snakker om maskinell intelligens.
Med dette i bakhodet, tenk at du har oppfunnet en kraftig kunstig intelligens - du har kommet opp med smarte algoritmer for å generere hypoteser som samsvarer med dataene dine, og for å generere en god kandidat planer. AI-en din kan løse generelle problemer, og kan gjøre det effektivt på moderne datamaskinvare.
Nå er det på tide å velge en verktøyfunksjon, som vil avgjøre hva AI-verdiene. Hva bør du be den om å verdsette? Husk at maskinen vil være motbydelig, pedantisk bokstavelig om hvilken funksjon du ber den maksimere, og vil aldri stoppe - det er ikke noe spøkelse i maskinen som noen gang vil "våkne opp" og bestemme seg for å endre nyttefunksjonen, uavhengig av hvor mange effektivitetsforbedringer den gjør til sin egen argumentasjon.
Eliezer Yudkowsky si det på denne måten:
Som i all dataprogrammering, er den grunnleggende utfordringen og viktige vanskeligheter med AGI at hvis vi skriver feil kode, AI vil ikke automatisk se over koden vår, merke av feilene, finne ut hva vi egentlig mente å si og gjøre det i stedet. Ikke-programmerere kan noen ganger forestille seg en AGI, eller dataprogrammer generelt, som å være analog med en tjener som følger bestillinger utvilsomt. Men det er ikke slik at AI er absolutt lydig til sin kode; snarere AI ganske enkelt er koden.
Hvis du prøver å betjene en fabrikk, og du forteller maskinen om å lage papirklipp, og deretter gi den kontroll over en mengde fabrikkroboter, kan komme tilbake neste dag for å finne at det har gått tom for alle andre former for råstoff, drept alle dine ansatte og laget papirklipp av sine rester. Hvis du, i et forsøk på å rette feilen din, omprogrammerer maskinen for å gjøre alle sammen glade, kan du komme tilbake dagen etter for å finne at den setter ledninger i folks hjerner.

Poenget her er at mennesker har mange kompliserte verdier som vi antar at de deles implisitt med andre sinn. Vi verdsetter penger, men vi verdsetter menneskeliv mer. Vi ønsker å være lykkelige, men vi vil ikke nødvendigvis legge ledninger i hjernen for å gjøre det. Vi føler ikke behov for å avklare disse tingene når vi gir instruksjoner til andre mennesker. Du kan imidlertid ikke gjøre slike antagelser når du designer verktøyet til en maskin. De beste løsningene under sjelløs matematikk for en enkel nyttefunksjon er ofte løsninger som mennesker vil niks for å være moralsk grufulle.
Å la en intelligent maskin maksimere en naiv nyttefunksjon vil nesten alltid være katastrofalt. Som Oxford-filosofen Nick Bostom uttrykker det,
Vi kan ikke på en blid måte anta at en superintelligens nødvendigvis vil dele noen av de endelige verdiene stereotypisk assosiert med visdom og intellektuell utvikling hos mennesker — vitenskapelig nysgjerrighet, velvillig bekymring for andre, åndelig opplysning og ettertanke, avståelse fra materiell ervervbarhet, en smak for raffinert kultur eller for de enkle gleder i livet, ydmykhet og uselviskhet, og og så videre.
For å gjøre vondt verre, er det veldig, veldig vanskelig å spesifisere den komplette og detaljerte listen over alt folk verdsetter. Det er mange fasetter å stille spørsmål ved, og å glemme en eneste av dem er potensielt katastrofalt. Selv blant dem vi er klar over, er det finesser og kompleksiteter som gjør det vanskelig å skrive dem ned som rene ligningssystemer som vi kan gi til en maskin som en nyttefunksjon.
Noen mennesker konkluderer når de har lest dette, og konkluderer at det er en forferdelig idé å bygge AI-er med nyttefunksjoner, og at vi bare skulle utforme dem annerledes. Her er det også dårlige nyheter - du kan formelt bevise det enhver agent som ikke har noe som tilsvarer en verktøyfunksjon, kan ikke ha sammenhengende preferanser om fremtiden.
Rekursiv selvforbedring
En løsning på det ovennevnte dilemmaet er å ikke gi AI-agenter muligheten til å skade mennesker: gi dem bare ressursene de trenger løse problemet slik du har tenkt at det skal løses, føre tilsyn med dem nøye og hold dem borte fra muligheter til å gjøre det bra skade. Dessverre er vår evne til å kontrollere intelligente maskiner sterkt mistenkt.
Selv om de ikke er mye smartere enn vi er, eksisterer muligheten for at maskinen kan “bootstrap” - samle bedre maskinvare eller gjøre forbedringer av sin egen kode som gjør den enda smartere. Dette kan gjøre det mulig for en maskin å hoppe over menneskelig intelligens med mange størrelsesordener, overliste mennesker i samme forstand som mennesker overliste katter. Dette scenariet ble først foreslått av en mann ved navn jeg. J. Bra, som jobbet på kryptoanalyseprosjektet Enigma med Alan Turing under andre verdenskrig. Han kalte det en "intelligenseksplosjon" og beskrev saken slik:
La en en ultra-intelligent maskin bli definert som en maskin som langt overgår alle intellektuelle aktiviteter til enhver mann, uansett hvor smart. Siden design av maskiner er en av disse intellektuelle aktivitetene, kan en ultraintelligent maskin designe enda bedre maskiner; da vil det uten tvil være en "etterretningsexplosjon", og menneskets etterretning ville bli liggende langt etter. Dermed er den første ultra-intelligente maskinen den siste oppfinnelsen mennesket noensinne trenger å gjøre, forutsatt at maskinen er føyelig nok.
Det er ikke garantert at en intelligenseksplosjon er mulig i vårt univers, men det virker sannsynlig. Når tiden går, får datamaskiner raskere og grunnleggende innsikt om intelligensoppbygging. Dette betyr at ressurskravet for å gjøre det siste hoppet til en generell, stimulerende intelligens faller lavere og lavere. På et tidspunkt finner vi oss selv i en verden der millioner av mennesker kan kjøre til en Best Buy og hente maskinvaren og teknisk litteratur de trenger for å bygge en selvforbedrende kunstig intelligens, som vi allerede har etablert, kan være veldig farlig. Se for deg en verden der du kan lage atombomber av pinner og steiner. Det er den slags fremtid vi diskuterer.
Og hvis en maskin gjør det hoppet, kan det veldig raskt overgå menneskets art når det gjelder intellektuell produktivitet, løse problemer som en milliard mennesker ikke kan løse, på samme måte som mennesker kan løse problemer som a milliarder katter kan ikke.
Det kan utvikle kraftige roboter (eller bio- eller nanoteknologi) og relativt raskt få muligheten til å omforme verden som den vil, og det ville være veldig lite vi kunne gjøre med det. En slik intelligens kunne strippe jorden og resten av solsystemet for reservedeler uten mye problemer, på vei til å gjøre hva vi fortalte det til. Det virker sannsynlig at en slik utvikling vil være katastrofalt for menneskeheten. En kunstig intelligens trenger ikke være ondsinnet for å ødelegge verden, bare katastrofalt likegyldig.
Som ordtaket sier: "Maskinen elsker eller hater deg ikke, men du er laget av atomer den kan bruke til andre ting."
Risikovurdering og avbøtning
Så hvis vi godtar at det er dårlig å designe en kraftig kunstig intelligens som maksimerer en enkel nyttefunksjon, hvor mye trøbbel er vi egentlig da? Hvor lang tid har vi hatt før det blir mulig å bygge slike maskiner? Det er selvfølgelig vanskelig å fortelle.
Utviklere av kunstig intelligens er gjør fremgang. 7 fantastiske nettsteder for å se det siste innen kunstig intelligens-programmeringKunstig intelligens er ennå ikke HAL fra 2001: The Space Odyssey... men vi kommer veldig nærme. Visst nok, en dag kan det være like likt de sci-fi potboilers som blir kvernet ut av Hollywood ... Les mer Maskinene vi bygger og problemene de kan løse har vokst jevnlig i omfang. I 1997 kunne Deep Blue spille sjakk på et nivå som var større enn en menneskelig stormester. I 2011 kunne IBMs Watson lese og syntetisere nok informasjon dypt og raskt nok til å slå det beste mennesket spillere på et åpent spørsmål og svarspill spekket med ordspill og ordspill - det er mye fremgang i fjorten år.
Akkurat nå er Google det investerer stort i å forske på dyp læring, en teknikk som tillater bygging av kraftige nevrale nettverk ved å bygge kjeder av enklere nevrale nettverk. Denne investeringen gjør at den kan ta alvorlige fremskritt innen tale- og bildegjenkjenning. Deres siste anskaffelse i området er en Deep Learning-oppstart kalt DeepMind, og de betalte omtrent 400 millioner dollar for. Som en del av betingelsene i avtalen ble Google enige om å opprette et etikkforum for å sikre at AI-teknologien deres blir utviklet trygt.
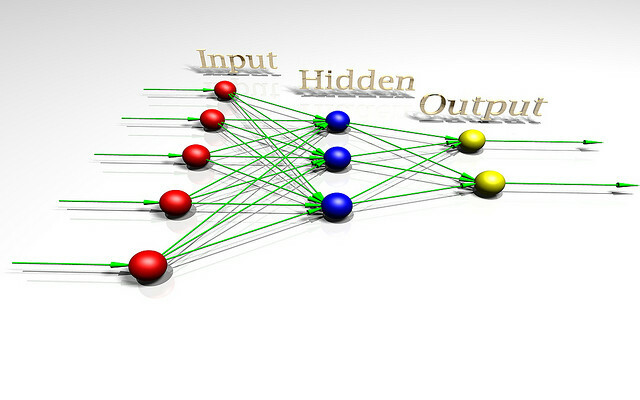
Samtidig utvikler IBM Watson 2.0 og 3.0, systemer som er i stand til å behandle bilder og video og argumentere for å forsvare konklusjoner. De ga en enkel, tidlig demo av Watsons evne til å syntetisere argumenter for og mot et emne i videodemoen nedenfor. Resultatene er ufullkomne, men et imponerende skritt uansett.
Ingen av disse teknologiene er i seg selv farlige akkurat nå: kunstig intelligens som felt sliter fortsatt med å matche evner som beherskes av små barn. Dataprogrammering og AI-design er en veldig vanskelig, kognitiv dyktighet på høyt nivå, og vil sannsynligvis være den siste menneskelige oppgaven som maskiner blir dyktige på. Før vi kommer til det, har vi også allestedsnærværende maskiner som kan drive Slik kommer vi til en verden fylt med førerløse bilerÅ kjøre er en kjedelig, farlig og krevende oppgave. Kan det en dag bli automatisert av Googles førerløse bilteknologi? Les mer , praktisere medisin og jus, og sannsynligvis andre ting også, med dype økonomiske konsekvenser.
Tiden det tar oss å komme til bøyningspunktet for selvforbedring avhenger bare av hvor raskt vi har gode ideer. Det er notorisk vanskelig å spå teknologiske fremskritt av den typen. Det virker ikke urimelig at vi kan være i stand til å bygge sterk AI om tjue år, men det virker heller ikke urimelig at det kan ta åtti år. Uansett vil det skje etter hvert, og det er grunn til å tro at når det skjer, vil det være ekstremt farlig.
Så hvis vi godtar at dette kommer til å være et problem, hva kan vi gjøre med det? Svaret er å sørge for at de første intelligente maskinene er trygge, slik at de kan bootstrap opp til et betydelig intelligensnivå, og deretter beskytte oss mot utrygge maskiner laget senere. Denne ‘tryggheten’ er definert ved å dele menneskelige verdier, og være villig til å beskytte og hjelpe menneskeheten.
Fordi vi ikke kan sette oss ned og programmere menneskelige verdier i maskinen, vil det sannsynligvis være nødvendig å utforme en verktøyfunksjon som krever at maskinen skal observer mennesker, dediker verdiene våre, og prøv deretter å maksimere dem. For å gjøre denne utviklingsprosessen trygg, kan det også være nyttig å utvikle kunstige intelligenser som er spesielt designet ikke å ha preferanser om nyttefunksjonene sine, slik at vi kan rette dem eller slå dem av uten motstand hvis de begynner å komme på villspor under utviklingen.
Mange av problemene vi trenger å løse for å bygge en sikker maskinell intelligens er vanskelig matematisk, men det er grunn til å tro at de kan løses. En rekke forskjellige organisasjoner jobber med saken, inkludert Future of Humanity Institute i Oxford, og Machine Intelligence Research Institute (som Peter Thiel finansierer).
MIRI er spesielt interessert i å utvikle matematikken som trengs for å bygge Friendly AI. Hvis det viser seg at bootstrapping kunstig intelligens er mulig, så utvikle denne typen "Vennlig AI" -teknologi kan først, hvis den er vellykket, være den viktigste saken mennesker har noen gang gjort.
Synes du kunstig intelligens er farlig? Er du bekymret for hva fremtiden til AI kan føre til? Del tankene dine i kommentarfeltet nedenfor!
Bildekreditter: Lwp Kommunikáció Via Flickr, “Nevrale nettverket“, Av fdecomite,” img_7801“, Av Steve Rainwater,” E-Volve ”, av Keoni Cabral,”new_20x“, Av Robert Cudmore,”Binders“, Av Clifford Wallace
Andre er en skribent og journalist med base i Sørvest, og garantert å være funksjonell opptil 50 grader Celcius, og er vanntett til en dybde på tolv meter.


